Ton agent IA, plus affûté chaque jour
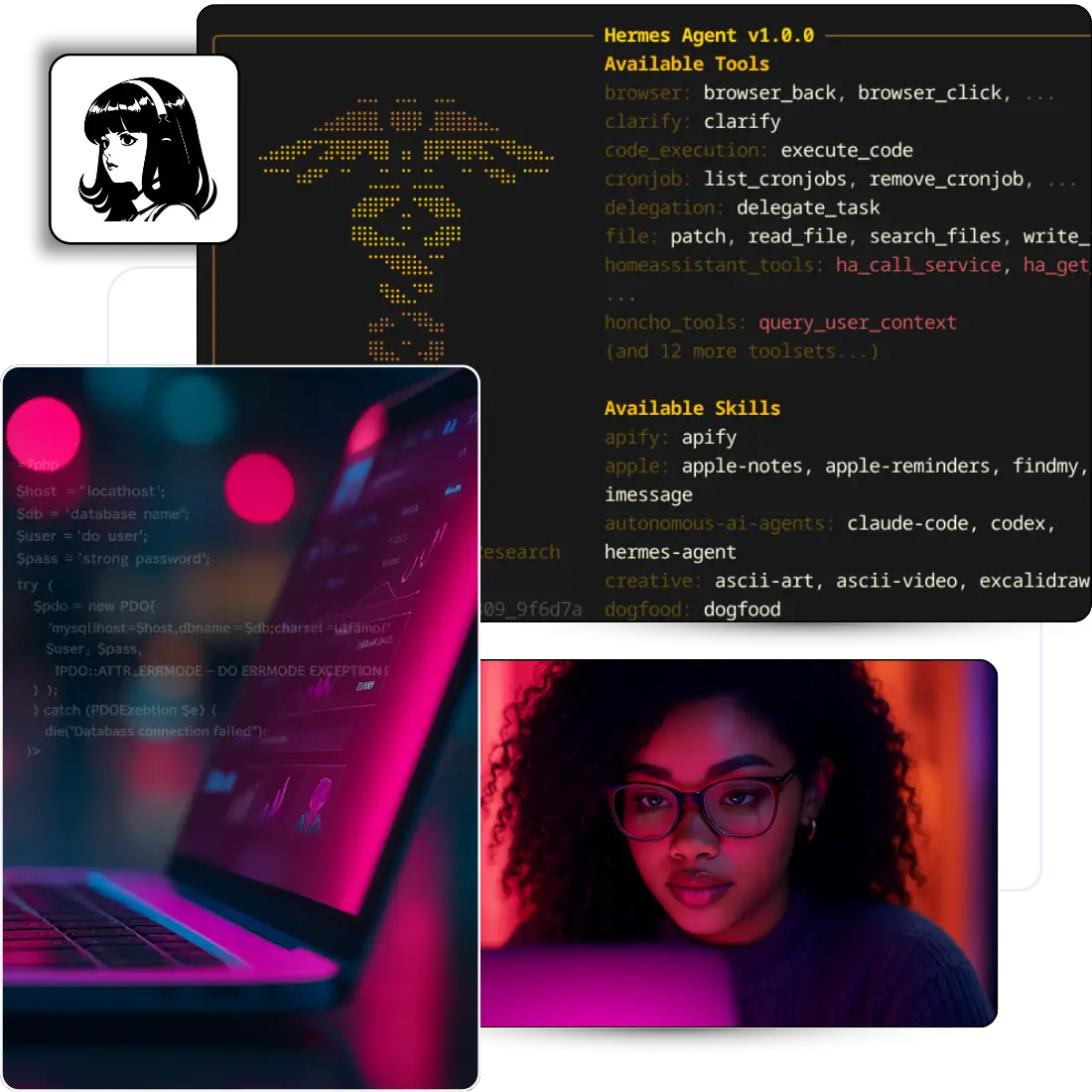
Hermes Agent est le runtime IA open-source de Nous Research. Tu le pointes vers n'importe quel LLM qui te plaît (Nous Portal, OpenAI Codex, Anthropic, OpenRouter, GLM, DeepSeek, modèles Ollama locaux et 15+ autres) et l'agent gagne en finesse au fil du temps, parce que la boucle d'apprentissage transforme les tâches répétées en skills réutilisables, écrits dans ~/.hermes/skills/.
Faire tourner Hermes sur un VPS garde l'agent en ligne 24/7. La mémoire persiste entre les sessions, les jobs planifiés continuent à tourner que tu sois à ton bureau ou en train de dormir, et c'est toi qui décides quels modèles, gateways ou intégrations tournent vraiment. Licence MIT, zéro télémétrie, aucune plateforme pour dicter ce que ton agent a le droit de faire.

















.svg)
.svg)
.svg)
.svg)
.svg)
.svg)
.svg)

.svg)
.svg)
.svg)
.svg)
.svg)




















.png)









